
Table of Contents
- 1. Summary
- 2. Context
- 3. Impact on Creators
- 4. Impact on the UK’s Creative Industries
- 5. Impact on Large Rightsholders
- 6. Impact on the British AI Ecosystem
- 7. Impact on the Wider R&D Ecosystem
- 8. Impact on the Wider Economy and Britain
- 9. Consequences for Policy-making
- 10. Authors
- 11. Acknowledgements
Summary
- Britain hosts world-class AI researchers and one of the global top AI labs, yet zero general-purpose LLMs have ever been trained on UK soil. This is because commercial text and data mining (TDM) – which every frontier model abroad relies on – is illegal here.
- A compulsory-licensing regime forces developers to hunt down and pay the right-holder for every paragraph, image or riff their model scans. This is a significant burden and a reason why general-purpose LLMs have not been trained in the UK. Since copyright does not bind globally, most labs choose to train in jurisdictions that have TDM exceptions and sell their products to the UK to avoid this regulatory burden.
- If Parliament tried to block access to non-compliant models, most providers would just geoblock the UK. That would cut the country off from frontier AI, driving talent, capital and tax receipts overseas almost overnight.
- Creators would hardly profit from compulsory licensing: even in a perfect system a 10,000-word essay might earn twenty pence, a lifetime of illustrations about £50.
- Meanwhile, the upside we forfeit is enormous: mainstream studies put generative-AI diffusion at ~1% extra productivity growth, roughly £28.5 bn a year. A licensing drag of just 30-50 base points wipes out £11.5-19.7 bn annually, compounding to £106-175 bn by 2035.
- By contrast, only £8.3 bn of the creative sector’s £124 bn GVA is plausibly exposed to open-web TDM, and the fast-growing parts of the creative industry (software, advertising and design sub-sectors, which represent 56 % of the total) would actually benefit from cheaper AI.
- A one-line fix, deleting “for non-commercial research” from §29A CDPA, would align the UK with Japan, China, and the US, letting any lawfully-accessed work be mined while leaving public reproduction fully protected.
- That choice would unlock sovereign model-training capacity, boost arts funding through higher tax receipts, and keep Britain at the sharp end of the AI revolution.
Context
The current debate over UK copyright and AI has been framed, often unhelpfully, as a clash between big tech and independent creators. In reality, the government must consider a narrower and more technical regulatory question: when an AI developer already has lawful access to a work that is publicly available, must they still obtain an entirely new licence before they can use that material to train an AI model? Or in other words, should lawful access depend on whether a human or a data collector is accessing content?
To answer that question, the government ran a consultation on AI & copyright that closed on the 25th of February, 2025. In it, four headline options were floated (table 1).
Table 1: An overview of the policy options being considered in the copyright and AI consultation
Option 0 | Option 1 | Option 2 | Option 3 |
Maintains current copyright laws, meaning commercial TDM is illegal. | AI models could only be trained on copyright works if an express licence is obtained. Firms providing services in the UK could not get around this requirement by training in other countries. | Introduce a broad exception allowing AI training on publicly available copyright works without permission. | AI can train on works unless right holders expressly opt out. |
At the heart of the debate lies the question of how the law deals with text and data mining (TDM). TDM is the automated copying, parsing and computational analysis of large volumes of data to discover patterns, facts and relationships that are impossible to spot by manual reading. Whilst patterns, facts and relationships are not protected by copyright law, because the software must store at least a transient copy of every work it examines, TDM implicates the copyright right of reproduction.
Successive governments have revisited the question of how UK copyright law should treat TDM, commissioning review after review. Each has reached the same verdict: Britain’s copyright framework needs to be reformed and made more liberal.
Table 2: Key moments when UK governments have specifically examined, proposed or changed a text-and-data-mining (TDM) copyright exception
Date (chron.) | What happened to the TDM exception? |
May 2011 | Hargreaves Review recommends the UK create a copyright exception for text-and-data analytics and lobby for one at EU level. |
Dec 2011 – Apr 2012 | The Copyright & Rights in Performances (Research, Education, Libraries and Archives) Regs 2014 bring §29A CDPA into force, allowing TDM only for non-commercial research. Due to EU level laws, expanding TDM for commercial uses is blocked. |
Mar 2021 | IPO launches “Artificial Intelligence & IP” call-for-views, proposing to widen §29A so TDM is lawful for any purpose. |
Jul 2022 | Government announces its intention to legislate a broad, no-opt-out TDM exception for commercial uses. |
1 Feb 2023 | In a Westminster Hall debate, Minister for Science, Research and Innovation George Freeman confirms the broad TDM plan “will not go ahead” after creative-sector backlash. |
17 Dec 2024 – 25 Feb 2025 | New “Copyright & Artificial Intelligence” consultation re-opens the question. It floats an opt-out scheme that would let AI developers mine works unless rightsholders reserve their rights. |
Under current laws, where a person or organisation already has lawful access to a protected work, any act of copying – including “scrapes” that feed a training corpus – still requires the right-holder’s permission, unless a statutory exception applies. The existing UK exception (Section 29A CDPA 1988) permits TDM “for the sole purpose of non-commercial research”.
This exception is unsatisfactory. Firstly, commercial developers cannot rely on it, which limits R&D. Secondly, the existing exception also does not allow sharing of copyrighted information between non-commercial organisations like NHS Trusts or academic institutions. Finally, it limits non-commercial organisations from collaborating with commercial organisations on projects.
Put simply, TDM is how AI models get their learning material. It involves gathering huge amounts of text, images, and other content from the web. That content is then cleaned and organised so computers can read it. The AI model studies it to find patterns in language, ideas, or styles. Importantly, the AI doesn’t remember the original content or copy it in its outputs, it learns from it by identifying patterns and trends, allowing it to generate entirely new outputs based on what it’s seen.
TDM is therefore integral to the building of AI. To date, all competitive general-purpose LLMs have been trained using TDM on the fair use principle (or equivalent depending on their jurisdiction) – they rely on the idea that transient, non-expressive copying of legally acquired works for statistical analysis is lawful without first obtaining permission from, or paying, each individual right-holder.
It is therefore no wonder that, despite being home to one of the world’s most renowned AI labs, there has never been a general-purpose LLM trained on British soil. This is because of our restrictive copyright laws. Even if every other barrier – capital, compute, talent – were overcome, this legal block alone would be enough to prevent the emergence of a ‘UK OpenAI’.
There are some who want our copyright laws to be further restricted in such a way that deployment would be impacted (option 1). In practice, this would render illegal any model whose developers cannot prove they obtained an explicit copyright licence for every work in the corpus, no matter where the training occurred. Because OpenAI, Google DeepMind, Anthropic and almost every other frontier lab have trained on trillions of public-web tokens that were never individually cleared, the safe course for them would be to geo-block the UK. British users would be cut off from lawful access to tools like ChatGPT, Gemini, Claude, Copilot, Midjourney and the growing ecosystem of downstream apps built on those APIs. Many users would likely resort to using VPNs.
In order to enforce licensing, these restrictions would rely upon transparency requirements, which would mean developers would be forced to publish lists of every copyrighted text, image and audio file their models ingest, and perhaps even trace the fractional influence of each work on every output. Such radical transparency is technically unfeasible, legally fraught (it would re-disclose many works under copyright), and commercially suicidal – no frontier lab will hand competitors a blueprint of its data pipeline.
Passing legislation of this kind would be catastrophic. It would cut the UK off from frontier AI: the fastest-advancing general-purpose technology in recent history. Talent, capital and infrastructure investment would leave almost overnight; productivity and tax receipts would follow. Domestic firms, barred from deploying key AI tools, would either fall behind or move operations abroad, eroding the country’s global competitiveness. In the longer run the country would face a structural growth gap and stark national-security dilemma.
This paper therefore examines the most plausible outcome if the government adopts a policy that requires licensing for AI model training: companies training in the UK would have to secure a licence that explicitly allows TDM from rightsholders for any material they use, even when they already possess lawful access. This regime would not hinder AI deployment (customers could still obtain models trained legally in other jurisdictions) and it would avoid transparency requirements that could affect developers’ commercial models.
Our paper explores the most likely long-term effects of this model on independent creators, the UK’s creative industries, large rightsholders, the British AI ecosystem, the wider British economy, and the UK’s geopolitical position.
Impact on Creators
Worries about the potential impact of AI on artists and creators are understandable. Artists are generally undervalued by society: their work enriches cultural life and contributes in a myriad of ways to progress.
Furthermore, British creators’ earnings have declined (figure 1), a process that started decades before the widespread release and use of generative AI models (ChatGPT was launched on 30 November 2022).
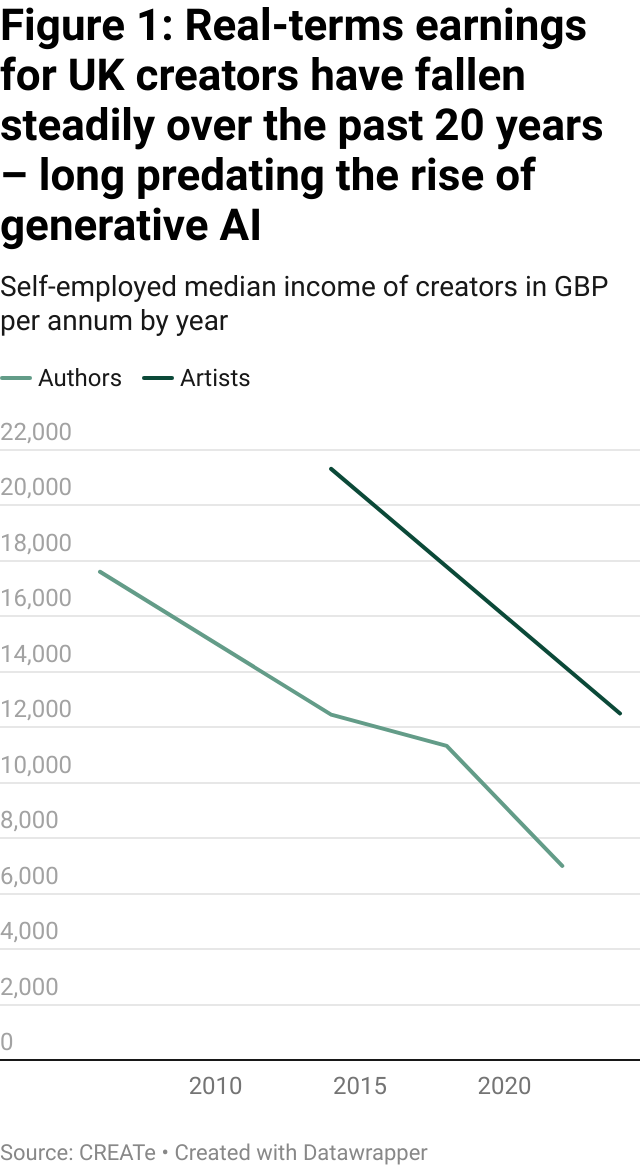
The creative industries have always followed “superstar economics”: earnings concentrate at the very top and sharply taper off for the vast majority of creators. In line with economic theory, gini coefficient data in the UK shows that wage inequality is most acute in the cultural sector. Professional authors post a Gini of 0.70 and visual artists 0.61 (0 signifies perfect equality, 1 is perfect inequality) – figures that tower over the whole-economy employee Gini of 0.36 and even beat sectors typically branded as unequal, such as tech/ICT (≈ 0.42).
Digitisation has intensified this pattern. Global platforms remove distribution limits, while algorithmic rankings recycle popularity, and payout thresholds sideline unpopular work. Digitisation also reduces constraints on production, which means supply has explored and pushed median creators further down an already-steep curve. For example, in 2023, only 19% of 9.8 million tracked artists topped 1,000 monthly listeners. A study of 580,000 Youtube channels found the top 3% received up to 90% of all views in 2016. Digitisation has amplified the superstar dynamic, and is likely the reason why we have seen the median income of creators reducing over the last twenty years.
If we are concerned about income inequality in the arts, licensing is not the answer. Because any compulsory-licensing scheme would allocate payments in proportion to catalogue size or downstream usage, it inherits the same market effects. The bulk of AI-training royalties would accrue to the large rightsholders who already dominate revenues, while the median writer, musician or illustrator (whose earnings have fallen because the skew has grown) would see little or no benefit.
Achieving sustainable income has always been difficult for the median creator, and this is only getting harder. In this context, it is reasonable that the prospect that AI companies might extract value from artists’ work without compensation strikes many as unjust. But if the goal is to ensure that independent creators are fairly rewarded in the AI economy, then a licensing regime (particularly one enforced at the national level) is a spectacularly ineffective tool. This is because:
1. Licensing doesn’t bind globally
Copyright law is territorial. British law cannot prevent data hosted on UK servers or produced by UK creators from being scraped and used to train models in the US, Japan, or China. Any licensing or opt-out regime introduced in the UK would apply only within UK jurisdiction – meaning AI companies would continue to conduct their training operations abroad in more permissive jurisdictions to circumvent it. This already happens: US and China-based companies train on publicly available content from around the world, regardless of UK copyright rules. Any national scheme would not protect creators from their work being used elsewhere and would only off-shore AI development (as we describe later).
2. Most creators don’t own their training rights
Even if licensing were enforceable, most independent creators would still be excluded from its benefits because they do not, in practice, control the rights to their own data.
Much of the content online is hosted on platforms like YouTube, Instagram, TikTok, and X. These platforms’ terms of service grant themselves irrevocable rights to use uploaded content, including for AI training. Meta, Google, ByteDance, and others have already released models trained on user-generated data, all within the terms users accepted.
Beyond platforms, many artists work under “work-for-hire” arrangements, especially in fields like illustration, photography, and design. These contracts usually transfer copyright to the commissioner (studios, agencies, or publishers) who are then free to license the work as they wish. In other words, even in the unlikely event that AI developers did license training data directly, the proceeds would go to Marvel or Disney, not the artist they commissioned.
3. Licensing is logistically difficult
There is a third, more prosaic concern. Generative AI models are trained on billions of individual data points: images, texts, songs, video frames gathered from all corners of the web. These works often lack copyright metadata or attribution, and few independent creators formally register their rights. It is an open and ongoing discussion as to how to determine when copyright actually exists and who can assert it: what if there is metadata but it points to someone who is not entitled to that licensing revenue? The large portion of public data is orphaned with no way to ask the creator for permission to use it.
Moreover, once data is used in training, its influence on the model becomes statistically diffuse. Unlike a search engine or streaming service, a model like GPT or Claude does not retain a copy of your work; it retains patterns. So there is no reliable way to track whether a specific creator’s work meaningfully influenced an AI system’s output.
Any licensing model would likely need to bundle and pool rights at scale, favoring large rights-holders, libraries, and platforms. This would bias rewards towards entities that own vast collections of data (like Getty, Adobe, or Google), not individual creators. Even assuming a system could be designed to pay creators, it would likely resemble current music royalty structures: mediated by third parties that take a cut and heavily skewed towards top earners.
Let’s Assume It Worked Anyway
These three factors mean it would be highly unlikely that independent artists will directly receive much revenue from a licensing regime implemented in the UK. AI companies will simply train abroad to skirt requirements in the UK. Where they do use data that is already owned by platforms or commissioners, independent creators are very unlikely to see much of the proceeds, which would flow instead to platforms like Bytedance or big commissioning studios like Disney.
But suppose all the logistical and legal obstacles were resolved. Suppose AI developers did license training data from individual creators, and that payments reliably flowed to the right people. What would they actually earn?
We can begin with a basic benchmark. Meta’s LLaMA 4 was trained on roughly 30 trillion tokens of text at a cost of around £630 million. If creators were compensated pro rata based on the volume of training data, the effective rate would be around £0.000021 per token. At that rate, a 10,000-token essay would earn its creator just 20 pence.
Visual content offers a similarly bleak picture. DALL·E 3 and other large-scale image models are typically trained on datasets of around 1 billion images. Training costs are estimated at approximately £24 million, implying a value of about 2 pence per image. For an illustrator with a portfolio of 1,000 works, this would amount to just £24 spread over an entire career. These numbers suggest that Picasso (who created an estimated 147,800 pieces of art during his career) would earn about £2,756 for his entire life's work.
But maybe this is because the models are “just not valuing the data properly!” Once you start playing around with the numbers, it quickly becomes evident that this cannot be the case. Even if you redistribute all of OpenAI’s projected global revenue in 2025 (which is estimated to amount to ~£9.44 billion) exclusively to people working in the creative industries only in the UK, each person would merely receive ~£3,900 a year.
The actual payments observed in real-world licensing deals roughly align with these figures. In 2024, Microsoft signed an agreement to license academic content from Taylor & Francis. If the total payment from that deal were evenly distributed across all the publisher’s articles, each one would be worth about £1.50. Similarly, Google’s licensing agreement with Reddit involved a substantial sum, but if divided among Reddit’s daily active users, each user would receive only 18 pence. These deals might not be representative of how licensing would function at scale but they do reveal the underlying economics: the unit value of individual contributions is vanishingly small.
Even under generous assumptions, licensing offers creators only token compensation. The economics don’t scale. For most independent artists and writers (even those with large online portfolios) such a system would offer negligible financial reward.
Impact on the UK’s Creative Industries
In recent debates over AI and copyright, much has been made of the supposed threat to the UK’s creative industries. Opponents of proposed copyright exceptions frequently cite the headline figure that the creative sector contributes £124 billion annually to the UK economy. On the surface, this number is meant to imply that a major pillar of the national economy would lose compensation from AI training if the UK were to adopt liberal copyright regimes. But a closer examination reveals that this claim is misleading.
Let’s break that figure down.
Table 3: GVA in the creative industries sub-sectors, 2023
Sub-sector | GVA (£ billion) | Percentage of Creative Industries’ GVA | Percentage of Total UK GVA |
IT, software, and computer services | 49.1 | 39.6% | 2.07% |
Advertising and marketing | 21.5 | 17.3% | 0.91% |
Film, TV, radio, and photography | 21.2 | 17.1% | 0.90% |
Publishing | 11.6 | 9.4% | 0.49% |
Music, performing, and visual arts | 11.2 | 9.1% | 0.47% |
Architecture | 4.0 | 3.2% | 0.17% |
Design and designer fashion | 3.9 | 3.1% | 0.16% |
Museums, galleries, and libraries | 1.1 | 0.9% | 0.05% |
Crafts | 0.4 | 0.3% | 0.01% |
Total Creative Industries | 124.0 | 100% | 5.2% |
Nearly 40% of the £124 billion comes from the software and computer services sector. Software source code is rarely public, and companies in this space typically don’t rely on copyright revenues. If anything, these firms stand to benefit from a more open AI training environment, which would support innovation and reduce regulatory barriers. That’s £49.1 billion immediately outside the scope of concern.
Add to that advertising and marketing, another 17% of the sector, or £21.5 billion. These industries don’t profit from copyrighted content directly, and they too would gain from enhanced AI capabilities. Now we’re at 56% of the total sector value.
Film, TV, and radio represent another £21.2 billion. But two‑thirds of British households take at least one subscription video‑on‑demand service and about 40% still pay for a traditional pay‑TV bundle. Taken together, this means that the majority of professionally produced screen content is now accessed through paid or licensed services rather than free‑to‑air channels. AI training on such works would not fall under a publicly accessible exception so these assets remain protected. We’re now at 73% of the creative industries’ value unaffected by any potential copyright relaxation.
Even within more obviously impacted areas like publishing, photography, music, and the visual arts, the risks are smaller than presumed. Consider publishing: of its £11.6 billion contribution, about £7 billion comes from books that are not publicly accessible. That leaves £4.6 billion potentially vulnerable – and even that may overstate exposure, given that academic publishing (which represents a large portion of this number) is also frequently behind paywalls.
Photography contributes £1.9 billion, but most photographers earn income through commissioned work rather than licensing. Being generous, we might say £1 billion could be impacted. As for music, live events make up the lion’s share of revenue (£6.1 billion out of £8.5 billion), leaving recorded music at £2.4 billion. And within that space, licensing opportunities have already been narrowing due to the rise of stock music services; AI is a new player in a game that was already shifting. Visual artists, too, face limited direct impact. A very generous assumption would suggest 25% of visual art revenue comes from licensing, translating to around £325 million in real exposure.
Altogether, even under generous assumptions, only about £8.3 billion, or 6.8% of the total £124 billion, represents sectors plausibly exposed to a reduction of licensing opportunities because of AI training on publicly available content.
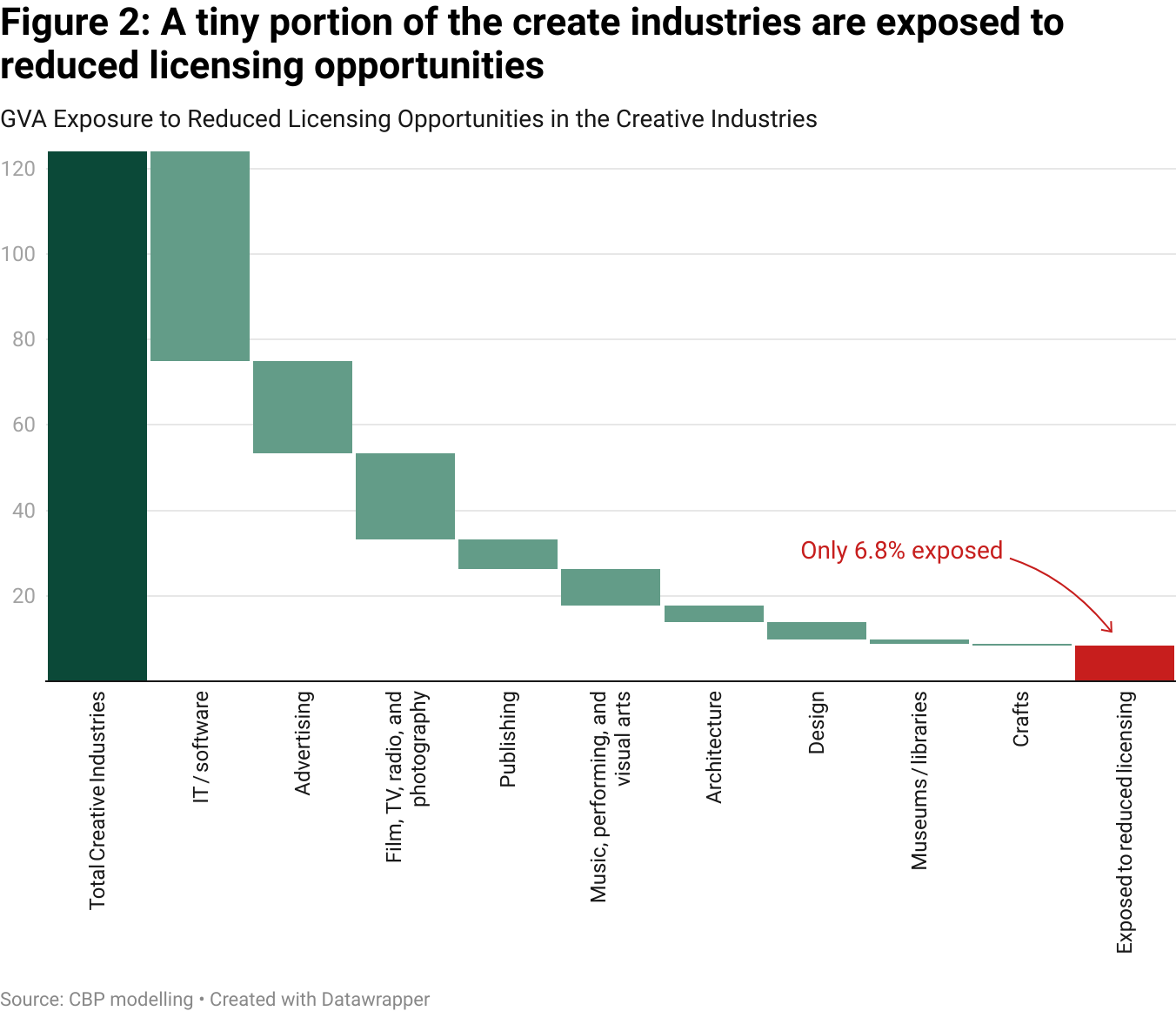
What will be the role of these sub-sectors in the future? Software and advertising are the only major sub-sectors that have experienced sustained growth since 2010. The other sub-sectors have stagnated or declined (figure 3). The growth opportunities in the creative sector as a whole seems to lie in sub-sectors that would stand to benefit from open AI training environments. It seems that a restrictive licensing regime like the one being put forward by campaigners might hurt rather than protect the future of the creative industries in the UK.
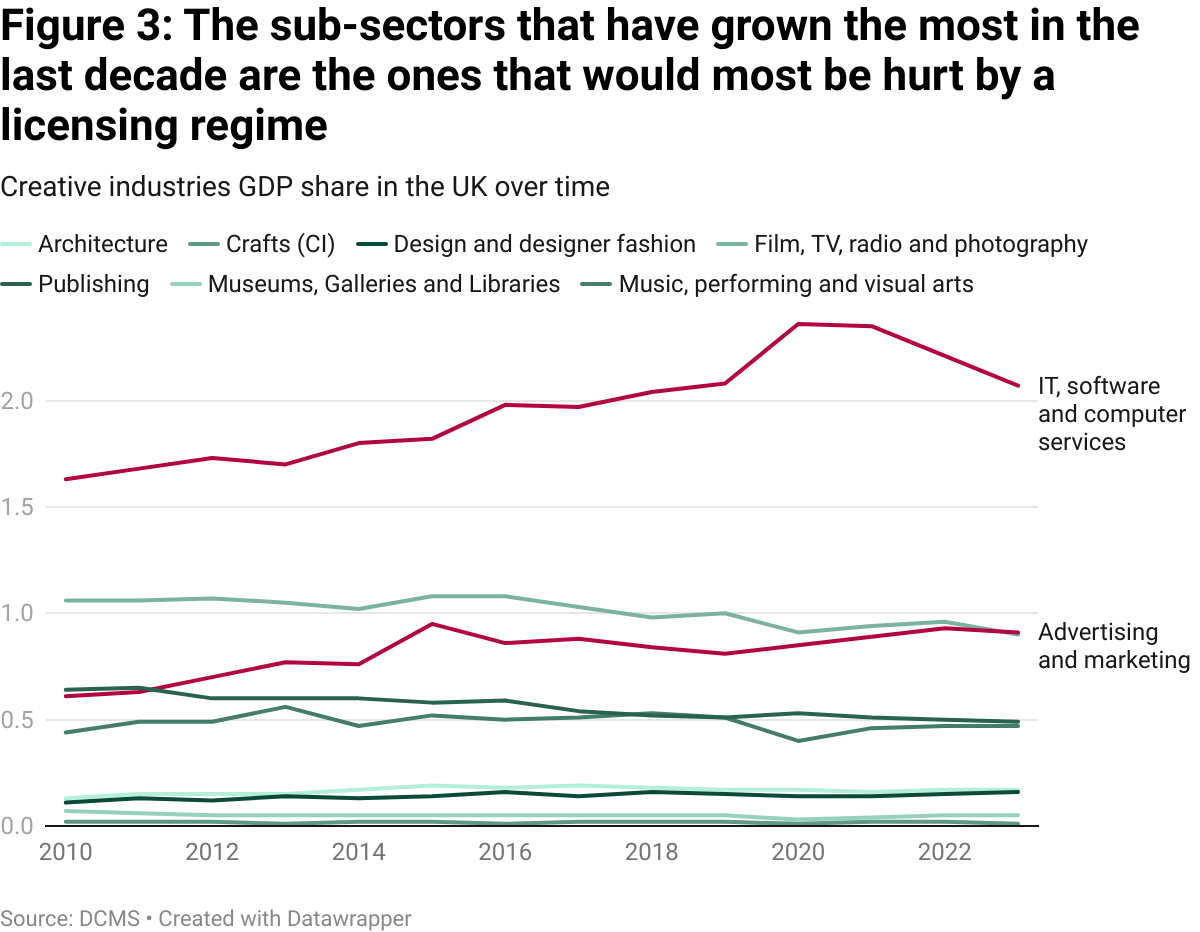
Focusing on licensing misses the point: the real disruption to the industry comes from AI‑generated substitute content. A licensing regime that taxes or restricts training data cannot stop synthetic music tracks competing for advertising slots, or photorealistic images crowding out stock photography libraries. The only thing a UK-only licensing rule would really achieve is to push the creation of AI substitutes offshore and restrict or slow down model release and adoption in the UK. The instinct to shield the creative sector is understandable. But relying on restrictive copyright frameworks that hurt the wider economy to do so would be a mistake.
Impact on Large Rightsholders
Licensing deals for model-training data are picking up speed, with rapidly rising revenues (table 4). Demand will keep increasing regardless of the UK’s policy decisions around copyright. This is because the biggest AI developers have, for the most part, already exhausted the well of publicly available text, images and code.
To keep advancing, these AI companies need vast reserves of fresh, high-quality content. Much like compute capacity and model architecture, access to data has become a competitive lever. That pressure is pushing labs to pay for private, well-curated datasets that cannot be scraped from the open web.
So far, licensing deals for AI training have most positively impacted the revenue streams of large rightsholders. These include:
- Media conglomerates (e.g. NewsCorp, Disney, Universal)
- Platform companies (e.g. Meta, Google, TikTok) that already own rights to vast amounts of user-generated content
- Stock media libraries (e.g. Getty Images, Shutterstock)
- Academic publishers (e.g. Elsevier, Springer, Taylor & Francis)
To date, the only significant licensing deals in the generative AI space have occurred between AI companies and these kinds of organisations. These deals have totalled millions of pounds. Most known commercial agreements have also covered news and news media content (68%), which is unsurprising given developers’ reliance on content that is up-to-date and regularly published for the accuracy of outputs (figure 4).
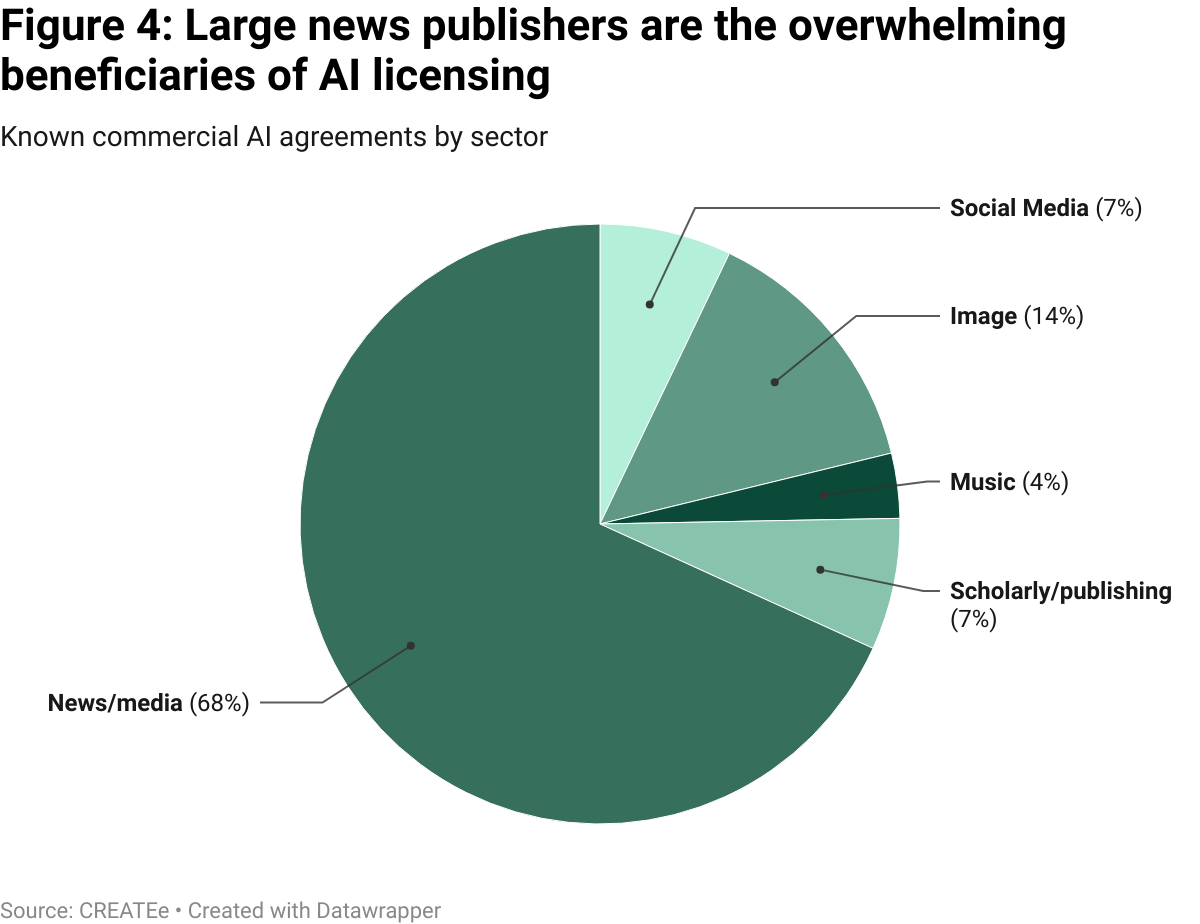
The fact these deals are being signed may superficially seem like a reason to think a licensing regime might work, benefitting the creative industry and creators themselves. There are, however, two reasons to suspect this may not be the case.
Firstly, for the large part, the content currently being licensed is not publicly available, meaning it wouldn’t have been eligible for use anyway under more open schemes like a TDM exception or an opt-out framework. These deals tend to involve paywalled or proprietary data, with added components like brand integration, indemnity, and premium access, things that cannot be obtained simply by scraping public web pages.
Furthermore, it is important to note that most of these rightsholders are under no obligation to pass revenue on to the original creators. The original journalists, photographers, or academics whose work underpins these deals often see none of the proceeds. Where redistribution does occur, as with Shutterstock’s Contributor Fund or Getty’s contractual royalty arrangements, the amounts are modest. Many deals, including high-profile agreements with NewsCorp, the Financial Times, and Reddit, make no public commitments to pay creators at all.
Finally, a critical nuance often lost in the debate is that the lucrative licensing agreements now being struck only have value because frontier models first reached a baseline of capability through unrestricted, large-scale TDM of the open web. Scaling to trillions of low-signal tokens is what allowed GPT-class systems to master general language patterns; beyond that point, additional web data produces sharply diminishing returns, so developers turn to smaller, high-quality datasets to fine-tune or refresh their models. In other words, premium content is valuable because it delivers incremental accuracy on top of an engine built with TDM; if the initial mass-scrape were prohibited, the subsequent fine-tuning market – and the licensing revenue that flows from it – would not exist.
Table 4: An overview of large-scale generative-AI licensing deals
Deal (AI ↔ Right-holder) | Rights licensed | Redistribution to individual creators? | Would a TDM exception (option 2) impact the deal? |
OpenAI ↔ Shutterstock (Jul 2023, 6-yr term) | Hi-res images, video, music & metadata; brand/API integration; enterprise indemnity. | Yes. Paid out of the Shutterstock Contributor Fund to every file used. | Minimal impact. Training copies could be free, but Shutterstock still sells clean masters, brand value and warranties, so a licence remains essential for good quality data. |
Nvidia ↔ Getty Images (Sept 2023) | Exclusive, watermark-free Getty archive for “Generative AI by Getty”; customer indemnities; contributor royalties. | Yes (contractual). Getty promises payments for any contributor content in the training set. | Minimal. A TDM exception wouldn’t grant access behind Getty’s paywall or the commercial “safe” warranty. |
OpenAI ↔ Associated Press (Jul 2023) | Historic text archive plus live news feed for ChatGPT answers. | Unclear. No public mechanism for per-journalist royalties. | Partial. Archive-training copies could be free, but OpenAI still needs the real-time feed and display rights. |
OpenAI ↔ Axel Springer (Dec 2023, “tens of millions €/yr”) | Training on archive and permission to show snippets from pay-walled Politico, Bild, BI, etc. | No automatic pass-through. Public terms speak only to corporate revenue. | Limited. Training on public articles might be free, but pay-wall bypass & display rights still need a licence. |
OpenAI ↔ News Corp (May 2024, ≈ $250 m/5 yrs) | WSJ, Times (UK), etc. archives; real-time content; headline/snippet display; brand use. | Not disclosed. No creator-royalty mechanism announced. | Limited. TDM freedom wouldn’t cover pay-wall or display rights. |
OpenAI ↔ Financial Times (Apr 2024) | Training on FT archive; permission for ChatGPT to surface attributed summaries, quotes & links. | Not specified. Deal struck with FT Group; no public pass-through. | Limited. Display/snippet rights and pay-walled access still require a contract. |
Google ↔ Reddit (Feb 2024, ≈ $60 m/yr) | API fire-hose of Reddit posts & metadata; commercial use for Gemini & Search; priority support. | No. Payment flows to Reddit Inc. | Some. Public posts could be scraped under TDM, but the deal secures guaranteed, structured, rate-limit-free access and brand use, so the contract still matters. |
Amazon ↔ New York Times (May 2025) | Full NYT, Athletic & Cooking archives for Alexa answers; training of Amazon models; links back to NYT. | Not specified. No automatic journalist royalty provision disclosed. | Limited. Voice playback of excerpts and pay-walled data lie outside a pure TDM carve-out. |
OpenAI ↔ Le Monde / Prisa Media (Mar 2024) | French & Spanish pay-walled news for training and in-chat summaries with links. | Not specified. No creator-royalty details published. | Limited. Training might be free, but display and pay-wall access still demand a licence. |
Microsoft ↔ HarperCollins (Nov 2024, 3-yr term) | Non-exclusive licence for selected nonfiction back-list titles to train Microsoft AI models; protective terms limiting verbatim reproduction. | Yes, opt-in. Authors offered $5 000 per book, split 50/50 with the publisher ($2 500 each). | Minimal. A broad TDM exception would let Microsoft copy books it already lawfully accessed, but the deal still guarantees clean, full-text files, structured delivery, legal indemnities and long-term access, services the exception wouldn’t provide. |
What would be the economic impact of licensing on large rightsholders in the UK?
To get a sense of the impact of strengthening these protections on rightsholders in the UK, we can run a thought experiment with generous assumptions. Imagine the government telling every AI developer, “for each pound you spend teaching your models, you must hand the same amount to the people who own the data you used in the training process.” What would be the benefit to rightsholders if we lived in this hypothetical world?
Training large LLM models currently costs around £8.2bn. Our thought-experiment would redirect an equivalent proportion of this money to copyright owners with a UK presence, but not all of this value would be “attributable” to the UK. Because some of the rightsholders in the UK are big international multinationals, they do not keep all of their catalogues and brands on the UK balance sheet. Only 79% of this money would actually stay in Britain.
We assume that the stronger copyright protection would increase the economic benefits of content production, which would stimulate the production of additional content. But those catalogues also risk losing value as AI makes it easier for anyone to remix or imitate existing works, so let’s assume their overall value falls by half. Even with that hit, the new payments would leave rightsholders slightly better off than they are today, nudging them to commission or create more books, music and film.
This generous assumption would suggest licensing would have a total impact of ~£250m of additional wages from the increased GVA, and an associated increase of ~£120m in profits. These values are largely driven by the estimated size of intangible assets in the creative sector (minus software and marketing) of around £12bn. While non-negligible, this increase in added value pales in comparison to what we might expect from AI adoption, which could increase UK GDP by roughly £28.5 billion of extra output each year across various sectors of the economy.
In any case, there are reasons to think that our assumptions are unrealistic and the gains to the rightholders will in fact be lower than the numbers produced by this thought experiment. It is clear that effectively doubling the training costs of AI companies for the privilege of carrying out their training runs in the UK, would in practice result in no companies ever training their models here. Furthermore, the figures used in our thought experiment are significantly below the value the sector currently generates to the UK economy.
Impact on the British AI Ecosystem
Imposing licensing requirements on training data functions is, in economic terms, a factor tax: it distorts incentives, encourages relocation by multinational technology firms (who dominate global AI innovation) and imposes disproportionate costs on domestic companies that lack the scale to absorb regulatory burdens.
Empirical research consistently shows that the location and intensity of innovation are highly sensitive to taxation and regulatory structures. Theory is already playing out. A recent survey of 500 developers, investors, and professionals in the British AI ecosystem found that 66% believe their work would need to move abroad if the UK imposes a licensing regime while other jurisdictions protect a TDM exception.
The costs of a restrictive copyright regime extend to include the ongoing erosion of AI talent (figure 5), research, and investment – most acutely to the US. This has serious implications for the UK’s position in the global landscape. While the UK has demonstrated the capacity for cutting-edge innovation, its relative lack of capital deployment has put it at a disadvantage to other leading economies. Layering additional restrictions on a core input (data) risks compounding these disadvantages. The likely outcome is a continued migration of talent and ideas, resulting in a loss on the public and private investments that are made to cultivate domestic expertise. Economic literature shows that exceptional talent has large spillover effects on the wider economy and a country’s R&D output. If we care about economic growth and technological and scientific progress, we should be incredibly concerned about the outflow of this talent.
More insidiously, such regulation entrenches incumbents, in effect supporting the domination of the UK market by big tech firms like Google and OpenAI. Big tech companies have the capital to pay for data, while local start-ups seldom do. A six-figure legal bill and advance royalty payment is trivial for a trillion-dollar platform, but can be existential for a five-person spin-out. Mandatory licensing therefore shifts the competitive battleground from engineering ingenuity to balance-sheet muscle, reinforcing incumbent dominance.
Furthermore, startups attempting to validate a new product idea cannot conduct commercial research without incurring licensing costs upfront, before they've built a prototype and (most likely) been able to fundraise. This creates further barriers to entry.
Economic theory offers three clear mechanisms that explain why this strengthens incumbents while deterring competition. First, classic regulatory-capture analysis shows that well-resourced incumbents often shape rules in their own favour. Second, mandatory licensing operates as a raising-rivals’-costs tactic, adding overhead that giants can absorb but start-ups cannot. Empirical work on economies of scale in compliance finds that fixed regulatory costs fall sharply with firm size. Finally, basic barriers-to-entry theory recognises that front-loaded legal fees and licensing hurdles lock would-be challengers out of the market. Together these strands explain why copyright rules can strengthen the incumbent moat – in effect benefiting large foreign tech firms while putting small domestic challengers at a disadvantage.
Copyright laws could also have knock-on impacts on inward investment. Investors around the world are putting money into building out AI infrastructure, with a special focus on data centres. The Stargate project will mobilise $500 billion over the next four years building new AI infrastructure for OpenAI in the United States. The UAE is attracting investments totalling ~$100 billion.
Recognising the benefits of private capital injections and the importance this infrastructure has for strategic leverage and sovereignty, the British government has taken some bold steps to attract investment into AI infrastructure in the UK, including treating data centres as Nationally Significant Infrastructure Projects in the Planning & Infrastructure Bill and launching AI Growth Zones. Efforts at attracting investment, however, would be stymied if we constrain what these data centres can be used for.
When asked what the UK could do to attract more AI infrastructure investment, some AI providers have cited, among many other issues, our restrictive copyright rules that would mean companies cannot train their models on data centres built in the UK. But how much of a barrier are the copyright restrictions really? This is hard to estimate, as training figures in the US are generally not public and virtually no large-scale training happening in the UK. The sources that do exist vary but it is reasonable to estimate that ~20% of data centre usage is attributable to training AI models – a minority but large enough to influence location decisions when alternative jurisdictions impose no such restriction.
However, possibly more important than current restrictions is the effect of policy uncertainty. Publishing, music and sports-rights lobbies are lobbying hard for a new “digital-use right” that would capture not only the training phase but every downstream inference. The mere prospect of per-query royalties is enough to spook financiers modelling ten- and fifteen-year pay-back schedules for half-billion-pound investments.
Furthermore, there are wider costs to having a hostile business environment to AI development in the UK – no amount of strategising will overcome this simple fact. We will not be getting the most out of inward investments (whether it be into physical infrastructure or elsewhere) if we create an inhospitable environment.
Data centre projects are long-lived assets; sites breaking ground today are expected to operate well into the 2040s. When the rules on training data, output licensing and transparency can swing on a late-night parliamentary amendment, the risk premium on UK builds rises sharply, especially when operators can choose jurisdictions where the legal contours are already settled. In short, financial incentives alone will not be enough. The UK will only unlock private capital if it has stable, predictable copyright and data-governance rules that give developers the confidence to plan for the long term.
Impact on the Wider R&D Ecosystem
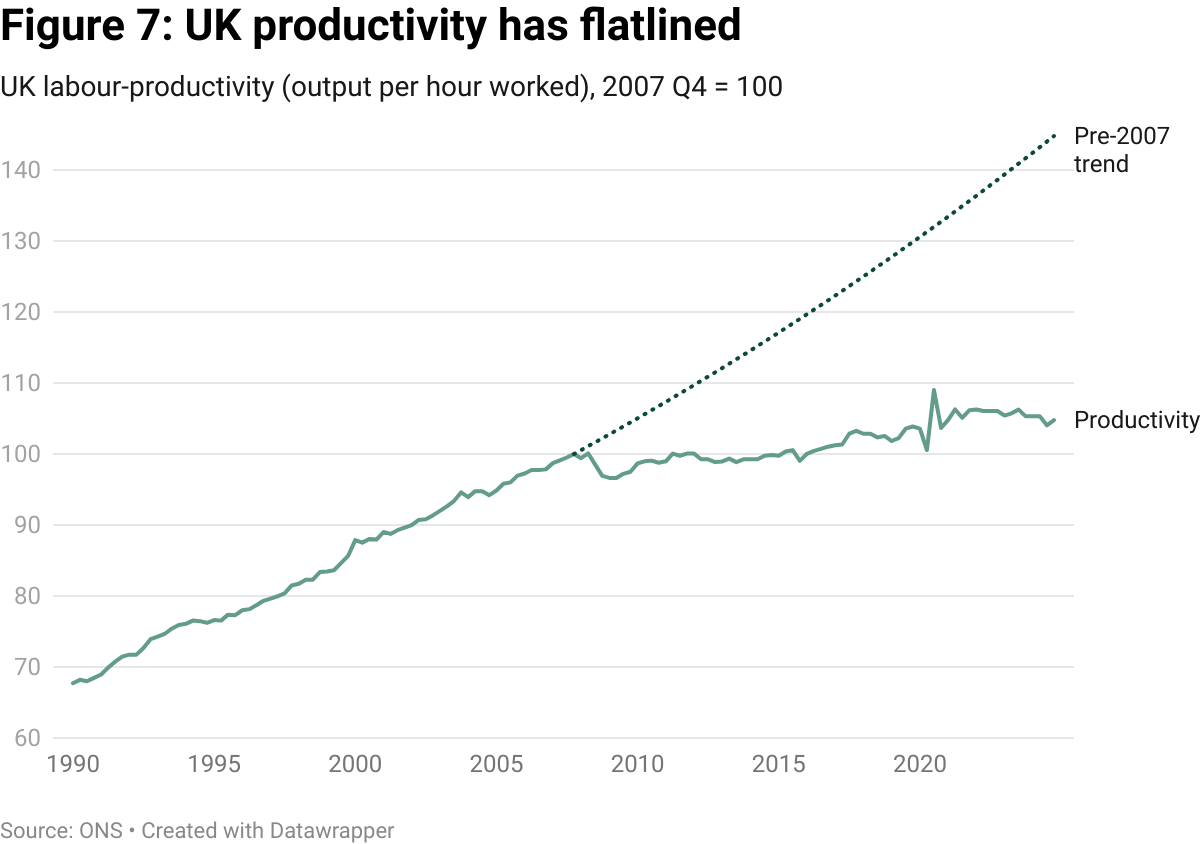
The UK already sits on one of the tightest TDM carve-outs in the OECD: section 29A CDPA only permits copying “for the sole purpose of non-commercial research” and forbids sharing the resulting dataset with commercial and non-commercial partners alike. In 2006, the Gowers Review warned that the UK’s intellectual-property rules were too rigid for the emerging digital era, with significant impacts on R&D and innovation. Almost twenty years later, the law has not budged.
The current copyright debate is aimed almost exclusively at generative models. By focusing on one type of AI model and its impact on one narrow sector of the economy, policy risks designing rules that suit the entertainment sector while undermining our strengths in science, health, and our wider STEM industries. Copyright is a body of law that impacts the entire economy – it makes no distinction between sectors or actors.
A restrictive regime (like the one we currently have in the UK) has real costs to our ability to conduct R&D flexibly and at scale:
- Licensing degrades scientific quality. Copyright restrictions harm reproducibility because peer verification requires re-licensing and/or re-scraping of the same material. Furthermore, when researchers cannot afford or negotiate access to full corpora, they settle for thinner, biased datasets. This has tangible negative effects on research quality: in drug discovery, that means missed protein targets; in medical diagnostics it means poorer predictions and, ultimately, worse patient outcomes.
- The costs to the taxpayer are material. A 2019 report by Universities UK estimates that the cost of the CLA Licence to the HE sector is over £15.5 million per annum, while the ERA licence costs £4.4 million per annum; this is on top of the primary subscriptions for journal and database access that costs the sector in excess of £192 million per year. This funding is diverted from laboratories, PhD stipends, and new equipment. The system also leads to clearly exploitative situations where researchers undergoing publicly funded work must pay publishers to text-mine taxpayer-funded papers. This means often the tax-payer pays for research four times: once for the original study, once for the publisher to host the paper, and once for the right to use that paper in AI-training data sets.
- Licensing demands fragments and discourages collaboration. Multi-centre projects have to re-license the same material again and again, injecting delay and administrative overhead into research. For example, because datasets produced under the current non-commercial TDM exception cannot be shared, NHS libraries must pay a per-article Copyright Fee Paid charge every time a new trust joins a study. This system disincentivises interdisciplinary research, as integrated projects (e.g. genomics × AI × clinical records) hit multiple rightsholders, which multiplies negotiations.
This does not take into account the significant upside for R&D represented by AI for science, which has the potential to drive breakthroughs across disciplines like biotech, energy, health and advanced manufacturing.
Impact on the Wider Economy and Britain
Relicensing for AI training data does not only impact the AI and creative industries. It would have effects on the wider economy as well as Britain’s geostrategic position in the world.
Lost Productivity Gains
Major studies predict that rapid diffusion of generative-AI tools could lift labour-productivity growth by 0.5-1.5 percentage points a year between now and 2035. Using 2024 GDP (£2.85 trillion), the midpoint (~ 1 pp) is worth roughly £28.5 billion of extra output each year — over three times the £8.3 billion plausibly exposed to competition through AI training on publicly available content. A compulsory licensing regime chips away at that upside in two ways:
- Higher input costs. Mandatory fees on training data act like a factor tax: they raise the marginal cost of new models.
- Slower diffusion. Productivity gains materialise only when frontier tools spread beyond “big tech” into retail, logistics, health, finance and the public sector.
Assuming even a 30-50 basis-point drag on annual productivity growth, the lost output mounts quickly: £8.6-14 billion a year today, compounding thereafter.
Furthermore, the modelling used to establish this midpoint only considers direct, first-order productivity effects (like task automation or labour re-allocation), which means it does not capture economic spillovers. Data is a non-rival input, so the same corpus can fuel breakthroughs across multiple fields simultaneously. When training data is fenced off behind compulsory licensing, we not only raise costs for the first use-case but also restrict sequential innovation that typically occurs when researchers and start-ups repurpose models for fresh challenges. Even a modest 10-20% reduction in those spillover benefits could erase another £2.9-5.7 billion of annual output today.
This means that a licensing regime would put the UK at risk of losing a total of £11.5-19.7 billion in lost productivity gains annually – a loss that would compound over time. By 2035 the economy is an estimated £106–175 billion (~ 3-5 %) smaller on direct effects alone, and as much as £210 billion smaller (~ 7.5%) once spillovers are included.
The UK already produces ~20% less output per hour than the United States and trails France and Germany by 10-15%. Layering a licensing drag on top of that gap risks locking in a further £90-215 billion annual handicap by 2035. This handicap would have significant effects on UK real wages (figure 6).
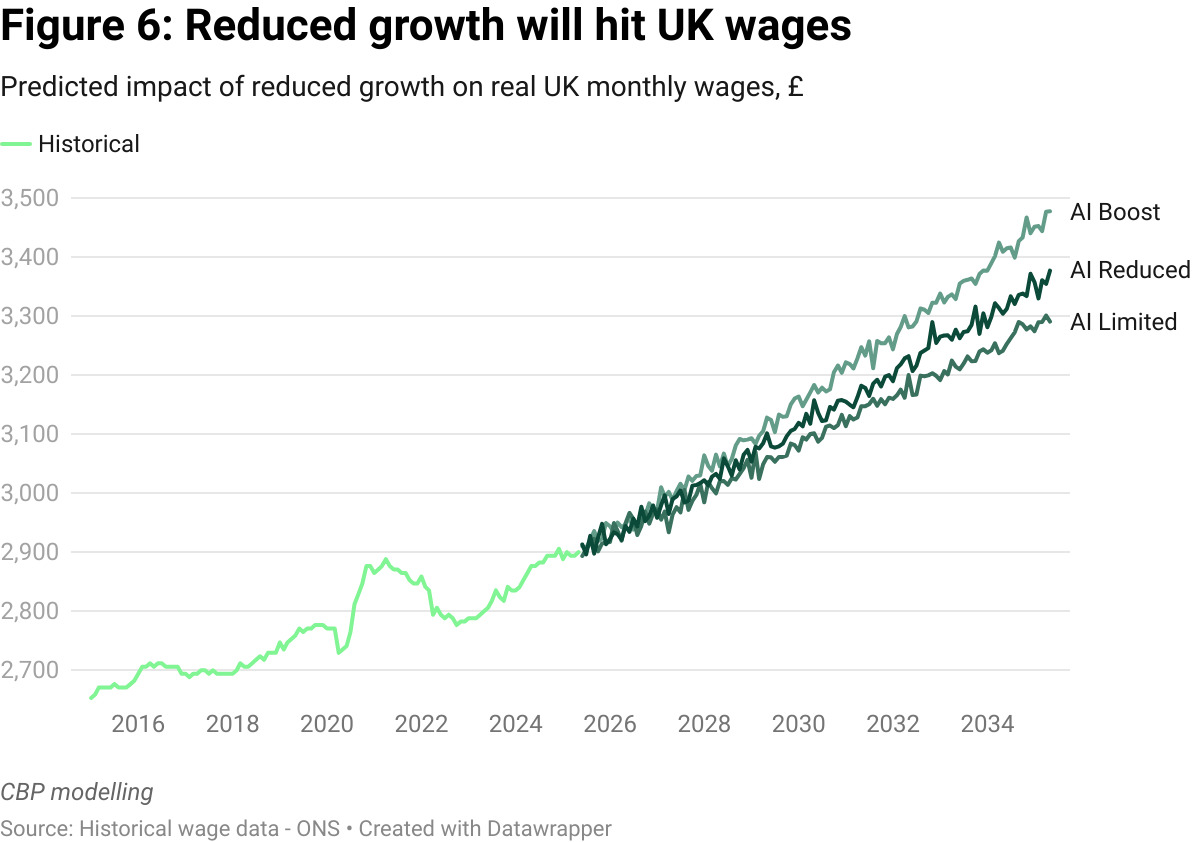
A drop in productivity would have a significant cost to living standards in Britain, which, of course, would impact all sectors, including the creative industries. It seems obviously wrong to handicap the entire economy, negatively influencing the wellbeing of the whole British population, for small returns to a single sector.
Fiscal Consequences
The fiscal effects of a licensing regime reflect its macroeconomic effects. If compulsory licensing reduces GDP, it automatically reduces tax revenues. In the UK, four major tax heads (PAYE, National Insurance, VAT, and corporation tax) together capture roughly 37% of national income. In practice, the elasticity of tax revenue to income is close to 1: a 1% fall in GDP typically leads to a 1% fall in tax revenue. That means for every £1 lost in output, the Treasury loses about 37 pence in foregone revenue.
A licensing drag could reduce annual productivity gains by £11.5-19.7 billion. Applying the 37% tax-to-GDP ratio, this implies an immediate fiscal hit of between £4.3 and £7.3 billion per year. That’s equivalent to more than double the annual core research budget of UKRI, or the entire annual budget of the Department for Culture, Media and Sport. Just a fraction of the lost revenue would be enough to dramatically expand the budget of Arts Council England, reverse a decade of underfunding in culture, and endow a new generation of grants, festivals, residencies, and grassroots arts initiatives.
Over time, the costs grow sharply. On direct effects alone, the economy would be £106–175 billion smaller by 2035 than it would otherwise have been. That translates into £39–65 billion in lost cumulative tax revenue. If we also account for foregone spillovers (the secondary gains that arise when AI tools are reused across sectors) the GDP gap rises to £210 billion by 2035. The corresponding fiscal loss climbs to nearly £78 billion.
Geostrategic and National Security Effects
An over-reliance on foreign technology could have significant implications for Britain and its place in the world, by putting our economy at risk of coercive leverage.
Training a general-purpose large language model (LLM) like the ones produced by OpenAI or Anthropic requires access to a large corpus of data. To date, every competitive LLM has been trained on the internet, including on copyrighted work. Training these kinds of AI systems has not been legally possible in Britain due to our copyright laws – so it is no wonder that we have not produced LLMs to rival those coming out of Silicon Valley or Hangzhou (that operate in far more flexible copyright regimes).
It is very likely that AI, as a general-purpose technology with the potential to reorganise economies, shift global dynamics, and have profound social impacts, will confer significant geostrategic benefits to the nations at the forefront of its development. There are various strong geopolitical and sovereignty-related arguments for governments prioritising its development in their jurisdictions. This report is not the place to explore these exhaustively but risks include:
- Resilience shocks: geopolitical tensions, export-control escalations, or sanctions could cut off access to frontier chips, model updates, or safety patches.
- Data sovereignty and privacy exposure: sensitive citizen or governmental data processed by foreign-owned clouds or models may be subject to extraterritorial subpoenas or surveillance.
- Disinformation & narrative control: external actors with superior generative models can shape information environments, influence elections, or undermine trust in institutions.
We will not run an argument for a fully sovereign model here, but make the point that if policymakers believe domestic capability matters, a permissive legal environment for training is a prerequisite.
Consequences for Policy-making
The Government has promised a full economic impact assessment of the copyright options now on the table and, later this year, a separate report on the role of copyrighted material in AI training. Those exercises must look beyond the immediate transfer of income to rightsholders. They need to surface the second-order effects this paper has charted: the cost of displacing model training overseas, the drag on productivity growth, the forgone tax receipts, and the wider implications for Britain’s position in the global AI race.
A statutory TDM exception remains the cleanest and most growth-friendly path. It would simply lift the “non-commercial only” limiter inside section 29A so that any lawfully obtained copy can be mined for the purpose of training or evaluating models. The creator’s work would still be protected against public reproduction; what disappears is an artificial toll on statistical learning. It should also permit the sharing of training data between project partners as is allowed in many other jurisdictions such as the US, Japan, Germany etc.
If Westminster cannot summon the votes for that, an opt-out regime of the kind embedded in the EU’s Article 4 DSM Directive is a second best option. It gives every author or photographer the right to fence off specific works, yet avoids imposing a blanket tax on everyone else’s innovation.
A permissive baseline does not leave creators stranded; it makes room for precisely the kind of market the industrial strategy already envisages. The proposed Creative Content Exchange should become the trusted clearing house for data that is not freely available on the open web: high-resolution film stills, raw studio masters, archival newspapers, etc. With transparent contracts, standard indemnities and an auditable payment rail that sends licence income straight to the individual right-holder, the Exchange would funnel revenue to the people who actually produce the material while giving AI developers certainty of supply, supporting both the creative and AI industries.
Licensing is a blunt instrument for industrial policy. If ministers want to nurture the creative sector they will get far more bang for the taxpayer’s buck by unblocking real-world investment. For example, Marlow Film Studios, now awaiting a planning decision, would anchor up to 4,000 jobs and £3.5 billion of private capital. The UK currently lags behind its European peers in public spending on culture, and real-terms support for the arts remains below 2010 levels. A better strategy would be to reverse that trend: increase direct funding, expand grants, and invest in education and infrastructure.
A flexible copyright framework (like a TDM exception) paired with a targeted, place-based industrial strategy offers a simple, positive-sum bargain: creators keep control, innovators keep building, and the wider economy captures the productivity windfall. Any move toward compulsory licensing would trade that upside for an illusion of protection. This misguided policy would off-shore innovation, shrink the tax base, and leave most creators exactly where they started.
Acknowledgements
Thank you to Ayesha Bhatti, Benjamin White, Mat Dryhurst, and David Lawrence for comments, advice, and feedback.
Correction: an earlier version of this document implied that economist Daron Açemoglu indicated a growth rate of TFP higher by 0.5pp. The correct figure for his estimate is between 0.55% and 0.71% over a decade.
For more information about our initiative, partnerships, or support, get in touch with us at:
[email protected]For more information about our initiative, partnerships, or support, get in touch with us at:
[email protected]